

Czasem stajemy przed potrzebą znalezienia specyficznego narzędzia, które ułatwiłoby codzienną pracę. Ja niedawno szukałem czegoś do wygodnego przeglądania faktów z Ansible AWX. Oczywiście istnieją projekty takie jak ansible-cmdb, ale nie znalazłem niczego, co w stu procentach odpowiadałoby moim potrzebom. Nie szukałem też bardzo wnikliwie, więc możliwe, że zaraz ktoś wskaże mi lepsze rozwiązanie. Z ciekawości postanowiłem sprawdzić, co na to powie funkcja „Build with AI” w Google AI Studio. Wpisałem prostą prośbę o zbudowanie narzędzia, które pobierze fakty z AWX, wyświetli je i pozwoli przeszukiwać. I tak zaczął powstawać projekt AFE.
Proces tworzenia, czyli dialog z AI
Już pierwsza odpowiedź wygenerowała aplikację, która w zasadzie robiła to, o co prosiłem. Zaintrygowany, zacząłem dopisywać kolejne prośby o nowe funkcje: a może dodać filtrowanie, widok tabeli przestawnej, eksport do CSV, a nawet wyszukiwanie oparte o zapytania w języku naturalnym z wykorzystaniem lokalnej instancji zgodnej z OpenAI API, takiej jak Ollama czy llama.cpp. Krok po kroku, zapytanie po zapytaniu, narzędzie rozrastało się do w pełni funkcjonalnej aplikacji webowej.
Efekt końcowy, jak na osobę, która nie zna technologii takich jak React czy Node.js, jest… sami oceńcie. Aplikacja działa w moim małym środowisku labowym, łączy się z AWX lub bazą danych. Jestem przekonany, że zawiera sporo błędów i mnóstwo niepotrzebnego kodu, ale robi to, co ma robić, i to jest dla mnie najważniejsze.
Cały ten proces doskonale pokazuje, jak ogromny potencjał drzemie w narzędziach AI do wspomagania tworzenia oprogramowania. Jednak największym problemem, a zarazem pokazem siły takich platform, jest to, że w zasadzie odcięcie projektu od AI Studio uniemożliwia mi dalszy samodzielny rozwój. Nie znam tych technologii na tyle, aby swobodnie modyfikować kod. To pokazuje pewne ryzyko uzależnienia się od ekosystemu, w którym powstało narzędzie. Oczywiście w tym momencie Google zaciera ręce.
A co właściwie robi sama aplikacja?
Na początek warto wspomnieć, że jest podzielona na dwie części: frontend, czyli to, co widzimy w przeglądarce, oraz backend, który łączy się ze źródłami danych. I to właśnie w backendzie znajduje się plik konfiguracyjny, w którym można sporo dostosować. To tam parametryzuje się połączenia do AWX czy bazy danych, ale również całą integrację z LLM. Można tam zdefiniować, jakiego modelu chcemy używać, podać jego adres i ewentualnie token. W tym samym pliku umieściłem też całego prompta, który instruuje model, jak ma tłumaczyć moje zapytania na filtry. Oznacza to, że jeśli ktoś ma większe pojęcie o promptowaniu ode mnie, może go sobie dowolnie zmodyfikować i sprawić, że funkcja wyszukiwania w języku naturalnym będzie działała o wiele lepiej.
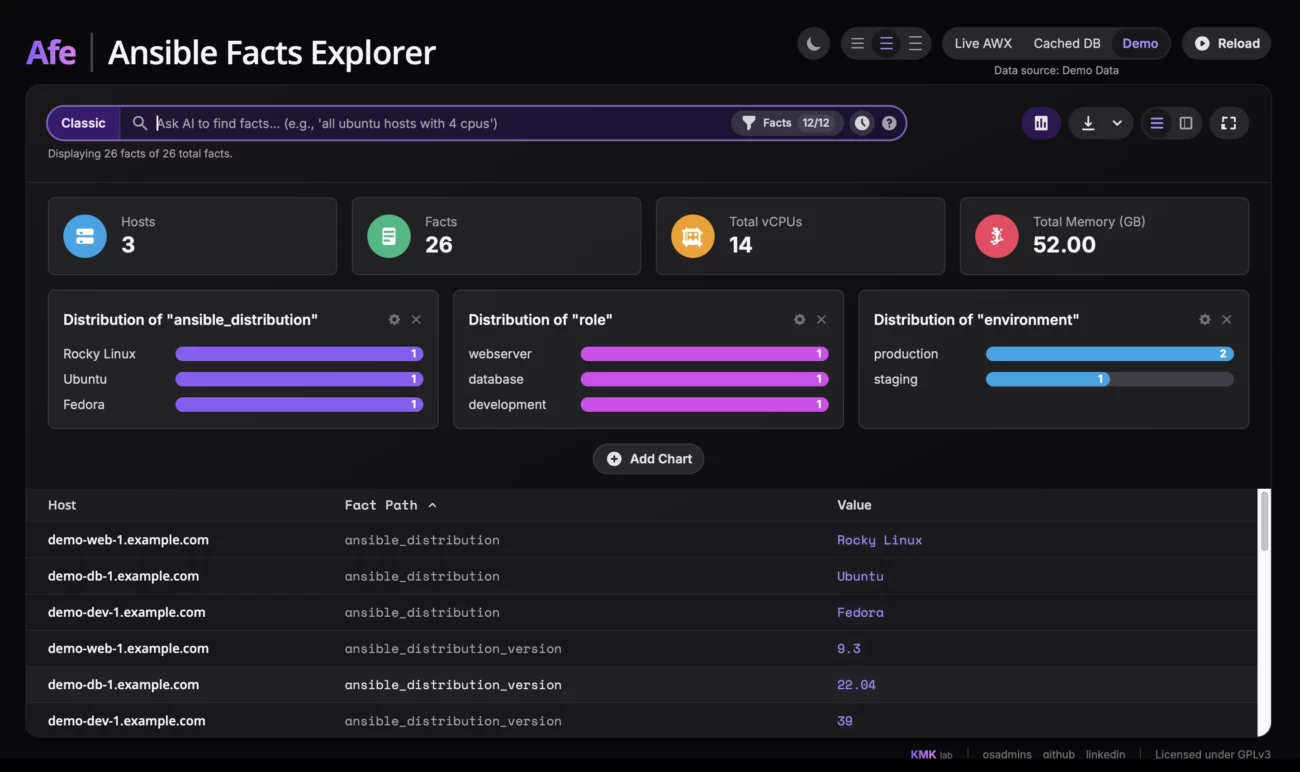
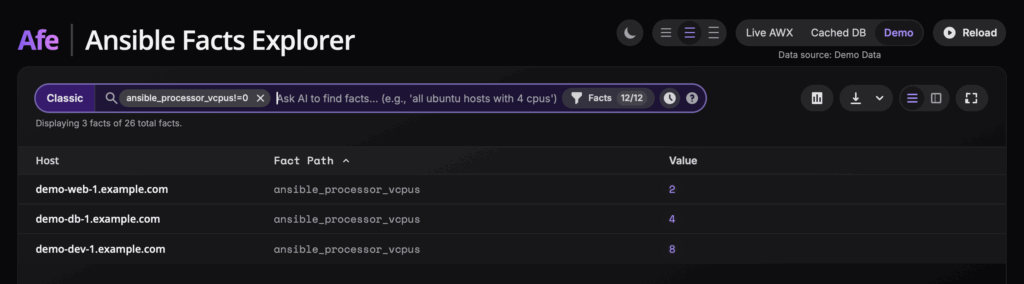
Jeśli chodzi o sam interfejs, jego głównym elementem jest wyszukiwarka. W klasycznym trybie pozwala filtrować dane za pomocą zwykłego tekstu, wyrażeń regularnych czy zapytań klucz-wartość w stylu vcpus > 4. Każde takie zapytanie można dodać jako „pigułkę” filtra, łącząc wiele kryteriów, aby precyzyjnie dotrzeć do szukanych informacji. Oczywiście jest też wspomniana eksperymentalna funkcja AI, gdzie po prostu wpisujemy, czego szukamy.
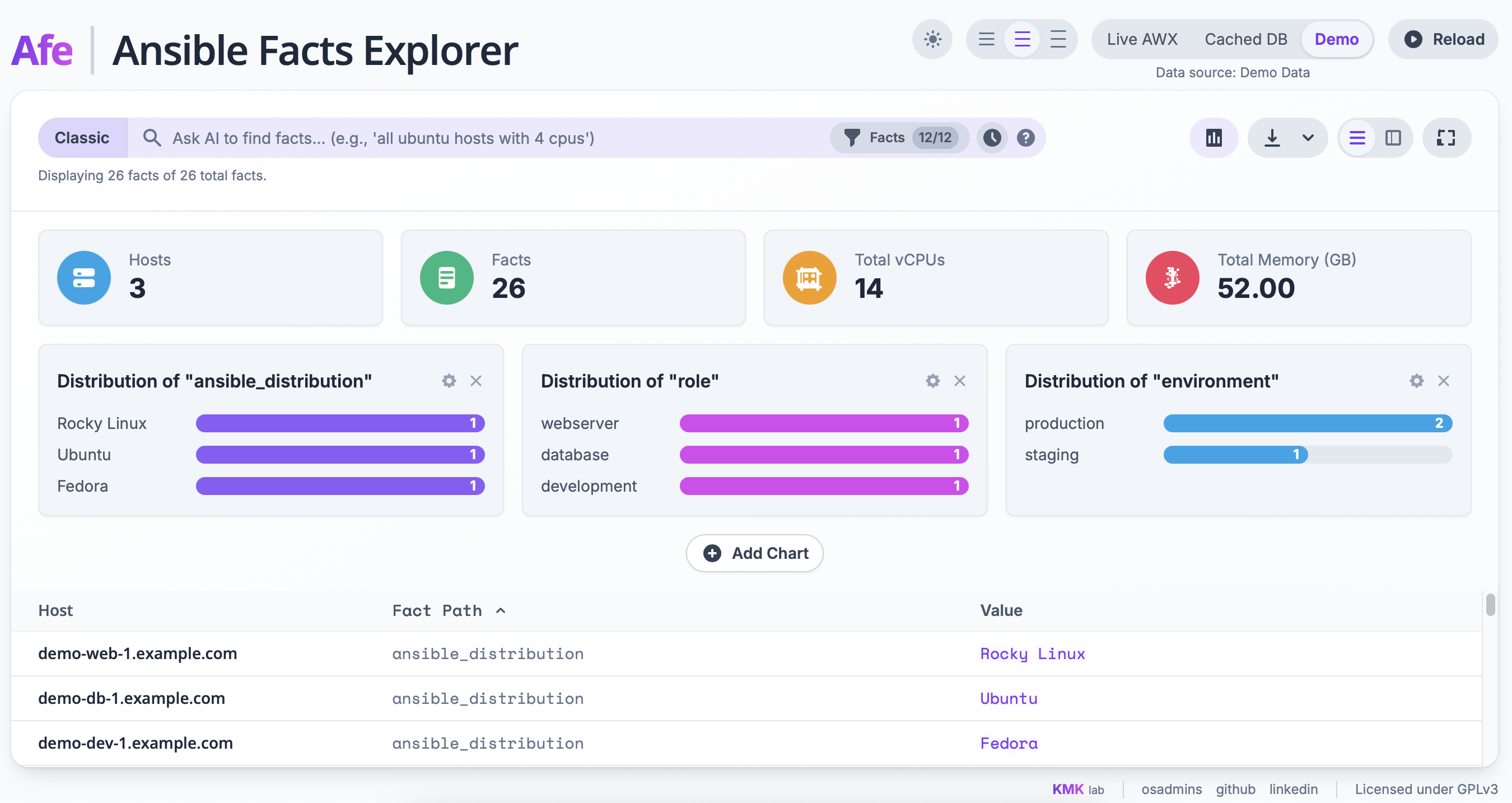
Tuż obok wyszukiwarki znajduje się również możliwość włączenia pulpitu nawigacyjnego, który wizualizuje nam fakty i daje szybki obraz całej infrastruktury. Wyświetla on kluczowe metryki, takie jak łączna liczba hostów, vCPU czy pamięci, a także konfigurowalne wykresy słupkowe, na których można zwizualizować rozkład dowolnego faktu, na przykład dystrybucji systemów operacyjnych. Po znalezieniu interesujących nas danych, można je wyświetlać na dwa sposoby: jako płaską listę wszystkich faktów lub w formie tabeli przestawnej. W tym drugim widoku każdy wiersz to host, a kolumny to konkretne fakty, co ułatwia porównywanie konfiguracji między maszynami. Aby nie utonąć w setkach kolumn, dodałem panel, w którym można dynamicznie wybierać tylko te fakty, które nas interesują, a także włączyć kolumnę z informacją o dacie zebrania danych, żeby wiedzieć, jak świeże są informacje.
Komfort pracy – jest jasny i ciemny motyw, możliwość zmiany zagęszczenia tabeli i tryb pełnoekranowy. Co ważne, nawet przy ogromnych zbiorach danych interfejs pozostaje płynny, bo zastosowałem wirtualizację tabel, która renderuje tylko widoczne wiersze. Na koniec, każdy przefiltrowany widok można w prosty sposób wyeksportować do pliku CSV lub XLSX (Excel), a format eksportu dostosowuje się do aktywnego widoku – listy lub tabeli przestawnej.
Ważna uwaga: To nie jest narzędzie produkcyjne
Muszę też zaznaczyć, że nie mam pojęcia, jak aplikacja zachowa się w dużym środowisku i stanowczo odradzam używania jej na produkcji. Została stworzona i przetestowana wyłącznie w małym labie. Nie wiem, jak bezpieczna jest sama budowa aplikacji, a ze względu na sposób jej powstania może zawierać błędy i podatności. Do projektu dołączyłem również instalator dla systemów bazujących na Red Hat, który automatyzuje cały proces wdrożenia, jednak on również nie był szeroko testowany i w niektórych sytuacjach może zawieść.
Zajrzyj na GitHuba i daj znać, co myślisz!
Jeśli jesteście ciekawi, co udało się stworzyć, cały projekt wraz z kodem i instrukcją instalacji znajdziecie na moim GitHubie https://github.com/kmkamyk/Ansible-Facts-Explorer