

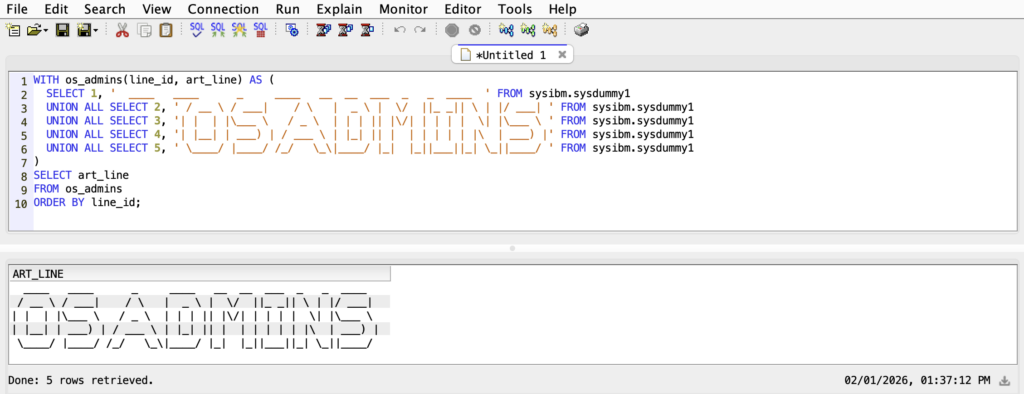
Dziś chciałem Wam pokazać jeden z najbardziej fascynujących i zaskakujących systemów operacyjnych, jakie powstały. To nie jest kolejny Unix, Linux ani Windows. To architektura, która poszła własną drogą i udowodniła, że inżynieria projektowania systemów może wyglądać zupełnie inaczej.
Mówię o dziecku IBM-a, które dla wielu może być synonimem „nudnych systemów bankowych”, a w rzeczywistości jest jednym z najbardziej bezkompromisowych projektów w historii IT. Kiedy my dzisiaj podniecamy się abstrakcją i wirtualizacją, myśląc, że odkrywamy nową ziemię, ten system robił to już dekady temu. Wyobraźcie sobie system, który nie zna pojęcia „pliku” w taki sposób, jak my go rozumiemy. System, gdzie wszystko jest obiektem, a cała pamięć dyskowa i operacyjna to jedna, wielka, płaska przestrzeń. Jeśli szukacie dowodu na to, że prawdziwa inżynieria nie potrzebuje buzz wordów, żeby rzucić na kolana, to zapraszam do lektury.
Rozdział 1: Fundamenty
Narodziny AS/400 (IBM i)
Aby zrozumieć ten fenomen, musimy cofnąć się do lat osiemdziesiątych i przenieść do laboratorium IBM w Rochester w stanie Minnesota. To właśnie tam narodził się projekt o kryptonimie „Silver Lake”. Inżynierowie stanęli przed karkołomnym zadaniem połączenia dwóch odmiennych światów. Z jednej strony mieliśmy System/38. Była to maszyna wyprzedzająca swoje czasy, posiadająca już wtedy zintegrowaną relacyjną bazę danych i nowatorskie zarządzanie pamięcią, ale była droga i trudna w obsłudze. Z drugiej strony istniał niezwykle popularny System/36, ceniony za prostotę i intuicyjny interfejs, choć architektonicznie znacznie prostszy. Celem projektu Silver Lake było stworzenie platformy, która zaadoptuje potęgę technologiczną Systemu/38 i ubierze ją w przyjazność Systemu/36. Efektem tych prac była premiera platformy AS/400 (Application System/400) w czerwcu 1988 roku. Należy zaznaczyć, że AS/400 odnosi się do sprzętu/platformy, podczas gdy OS/400 był dedykowanym systemem operacyjnym. Architektura zaprojektowana przez dr. Franka Soltisa nie była tylko kompromisem, ale technologicznym skokiem. Kluczowym założeniem była ochrona inwestycji klientów w oprogramowanie. Dzięki warstwie abstrakcji TIMI, firmy mogły przenieść swoje aplikacje ze starszych systemów na nową platformę bez konieczności przepisywania kodu od zera. To podejście zdefiniowało tożsamość systemu na kolejne dekady. Choć nazwa marketingowa zmieniała się wielokrotnie, od AS/400, przez iSeries, System i, aż po obecne IBM i, fundament wylany przez Soltisa w Rochester pozostał nienaruszony. To właśnie ta ciągłość sprawia, że program napisany w 1990 roku może działać natywnie na serwerze wyprodukowanym w bieżącym roku. Sprzęt w postaci AS/400 dziś już nie istnieje, ale system operacyjny pozostał i pracuje na platformie IBM Power.
Milisekundy decydują o milionach
I teraz pewnie zastanawiacie się, dlaczego w dobie chmury, wszechobecnych mikroserwisów i tanich serwerów x86 czy rosnących w siłę układów ARM, zawracam Wam głowę platformą której korzenie sięgają lat osiemdziesiątych. Odpowiedź jest prosta i sprowadza się do bezkonkurencyjnej wydajności w przetwarzaniu transakcji. IBM i to dzisiaj niewidoczny motor globalnej gospodarki, ukryty w serwerowniach największych banków, firm ubezpieczeniowych i centrów logistycznych. Kiedy płacicie kartą w sklepie, odbieracie paczkę od kuriera albo zlecacie przelew, jest spora szansa, że te operacje mieli właśnie ASior. Wielki biznes nie wybiera tej platformy z sentymentu, ale z kalkulacji. Modne dziś konteneryzacja i rozproszone klastry małych serwerów świetnie sprawdzają się w skalowaniu aplikacji webowych, ale dławią się przy gigantycznym obciążeniu bazodanowym, jakie generuje Core Banking czy systemy ERP wielkich firm. W tym świecie operacje muszą dziać się w czasie rzeczywistym. Tutaj nie ma miejsca na narzut komunikacyjny między mikroserwisami czy opóźnienia wynikające z architektury typowych serwerów. Kiedy trzeba przetworzyć miliony spójnych transakcji na sekundę, „zwykłe” systemy po prostu nie dają rady.
I tutaj postawie kropkę za tą małą małą indoktrynacją z mojej strony. Nie mam zamiaru wchodzić tu w wojny o to, co jest lepsze, a co gorsze. Chcę Wam po prostu pokazać te elementy, które moim zdaniem stanowią o absolutnej wyjątkowości tego systemu. Nie będę przy tym udawał obiektywizmu. Pracuję przy tych środowiskach na co dzień, wiem jak działają, znam ich potężne zalety, ale zdaję sobie sprawę również z ich wad. Dzisiaj jednak skupiamy się na czystej technologii, więc weźmy głęboki wdech i przyjrzyjmy się architekturze, która łamie wszystkie zasady, do jakich przyzwyczaiły nas popularne systemy operacyjne.
Bazodanowy system operacyjny
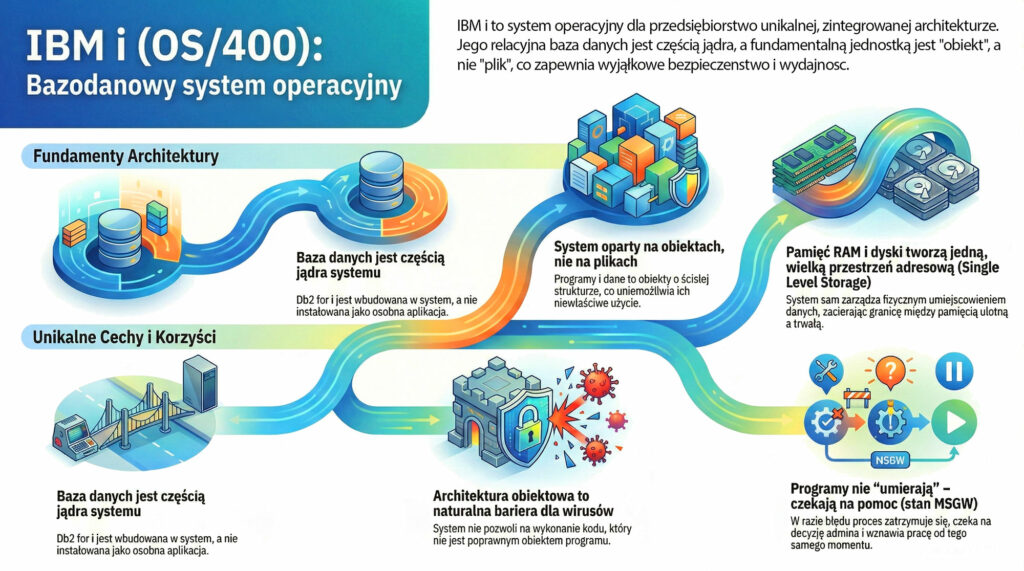
W świecie oprogramowania przywykliśmy do wyraźnego podziału. Mamy system operacyjny zarządzający sprzętem oraz bazy danych uruchamiane na jego wierzchu. W typowym środowisku Windows czy Linux baza danych, taka jak Oracle czy SQL Server, jest po prostu kolejnym programem, który trzeba kupić, zainstalować i osobno utrzymywać. W przypadku IBM i sytuacja wygląda zupełnie inaczej i to właśnie ten aspekt stanowi o absolutnej unikalności tej platformy. Tutaj relacyjna baza danych Db2 for i nie jest nakładką. Jest ona wbudowana bezpośrednio w jądro systemu, poniżej poziomu interfejsu maszynowego.
Ta architektura sprawia, że system operacyjny i baza danych tworzą nierozerwalną jedność. OS nie traktuje tabeli z danymi jak zwykłego ciągu bajtów na dysku, którego zawartość jest mu obojętna. System operacyjny doskonale „rozumie” strukturę danych biznesowych i traktuje tabelę SQL jak każdy inny natywny obiekt systemowy. Dzięki temu mechanizmy takie jak autoryzacja, zarządzanie przestrzenią czy blokowanie rekordów są realizowane na najniższym, najbardziej wydajnym poziomie jądra, a nie przez zewnętrzną aplikację walczącą o zasoby procesora. To podejście eliminuje narzut komunikacyjny i sprawia, że platforma od dekad dominuje w przetwarzaniu transakcyjnym OLTP, czyli krótkich transakcji w czasie rzeczywistym.
Obiektowa natura systemu
Filozofia tego systemu stoi w opozycji do uniksowego podejścia traktującego wszystko jako plik. W IBM i fundamentalną jednostką jest obiekt. Niezależnie czy mówimy o programie (*PGM), pliku danych (*FILE), czy profilu użytkownika (*USRPRF), każdy zasób posiada ściśle zdefiniowaną strukturę z nagłówkiem i częścią funkcjonalną. Taka konstrukcja podnosi poziom bezpieczeństwa poprzez mechanizm enkapsulacji. System po prostu nie pozwoli na edycję skompilowanego programu w edytorze tekstu ani na wykonanie kodu, który nie został poprawnie przetworzony. Dostęp do wnętrza obiektu możliwy jest wyłącznie przez zdefiniowane przez system interfejsy i komendy. Dzięki temu wirusy czy złośliwe skrypty próbujące nadpisać kod wykonywalny odbijają się od ściany już na poziomie systemu.
Abstrakcja sprzętowa i długowieczność kodu
Kolejnym filarem architektury jest warstwa TIMI (Technology Independent Machine Interface). Aplikacje pisane na ten system nie komunikują się bezpośrednio z procesorem, lecz z warstwą wirtualną. Dopiero niżej, warstwa SLIC (odpowiednik jądra i sterowników) tłumaczy te instrukcje na kod maszynowy konkretnego sprzętu. To genialne w swojej prostocie rozwiązanie zapewnia niespotykaną kompatybilność wsteczną. Program skompilowany dwadzieścia lat temu na procesorze o zupełnie innej architekturze zadziała dzisiaj na najnowszym procesorze POWER11 bez konieczności ponownej kompilacji. System samoczynnie dokona translacji instrukcji.
Single Level Storage
Unikalne podejście do bazy danych idzie w parze z nowatorskim zarządzaniem pamięcią, znanym jako Single Level Storage (SLS). To właśnie tę architekturę dr Frank Soltis wskazywał jako kluczowy czynnik decydujący o legendarnej wydajności tej platformy. Nie jest to zwykły mechanizm stronicowania, ale całkowita zmiana sposobu myślenia, która odróżnia ten system od rozwiązań konkurencji. W tym środowisku inżynier nie musi martwić się partycjonowaniem dysków, literami napędów czy punktami montowania, ponieważ te pojęcia tutaj po prostu nie istnieją. System traktuje całą dostępną pamięć RAM oraz wszystkie dyski twarde jako jedną, gigantyczną i płaską przestrzeń adresową. Dla procesora obiekt rezydujący na dysku jest dostępny pod konkretnym adresem w pamięci wirtualnej, dokładnie tak samo jak dane w RAM. To system operacyjny decyduje, gdzie fizycznie umieścić fragment pliku i kiedy przenieść go do pamięci operacyjnej, opierając się na częstotliwości dostępu. Administrator widzi jedynie pule pamięci (ASP), a mikrozarządzanie sektorami dyskowymi przestaje być jego problemem. Pozwala to na optymalizację operacji wejścia-wyjścia na poziomie nieosiągalnym dla klasycznych systemów plików, realizując wizję Soltisa o zatarciu granicy między pamięcią ulotną a trwałą.
Pule Dyskowe ASP
Koncepcja Single Level Storage, w której system widzi wszystkie dyski jako jedną, wielką przestrzeń adresową. Choć jest to genialne uproszczenie dla programisty, administratorzy infrastruktury czasem potrzebują fizycznie odseparować od siebie pewne grupy danych, czy to dla wydajności, czy dla bezpieczeństwa. Mechanizmem, który na to pozwala, zachowując jednocześnie zalety jednolitej adresacji, są Pule Pamięci Pomocniczej, czyli ASP (Auxiliary Storage Pool).
Każdy serwer IBM i posiada przynajmniej jedna pulę, zwaną System ASP lub ASP 1. To absolutne serce maszyny. Znajduje się tu system operacyjny, licencjonowany kod wewnętrzny oraz wszystkie dane użytkownika, które nie zostały celowo przeniesione gdzie indziej. W ramach tej puli jeden konkretny dysk pełni szczególną rolę, jest to tzw. Load Source, z którego maszyna zaczytuje mikrokod podczas startu. Dodatkowo administrator systemu może tworzyć tak zwane User ASP, numerowane od 2 do 32. Pozwala to na fizyczną izolację danych. Przykładowo, administrator może zbudować ASP nr 2 z bardzo szybkich dysków SSD i skierować tam intensywny ruch dzienników bazy danych, aby nie spowalniały one reszty systemu, nastomiast rzadko używane archiwa można przenieść na tańsze dyski talerzowe w oddzielnej puli. System daje jeszcze jedną możliwość zarządzania przestrzenią zwaną znane jako IASP (Independent ASP), numerowane od 33 do 255. W przeciwieństwie do podstawowych pul, IASP nie są „przyspawane” do systemu operacyjnego na stałe. Są to samowystarczalne kontenery z danymi, które można w dowolnym momencie logicznie podłączyć lub odłączyć od serwera bez konieczności restartu. To właśnie ta technologia jest fundamentem nowoczesnych rozwiązań High Availability (PowerHA). W przypadku awarii serwera głównego, IASP z całą bazą danych jest po prostu odpinany od uszkodzonej maszyny i przepinany do serwera zapasowego
Fundament sprzętowy
Wszystkie opisane powyżej mechanizmy, od zintegrowanej bazy danych po Single Level Storage, nie wiszą w próżni. Ich działanie jest możliwe dzięki połączeniu z platformą sprzętową IBM Power. Są to potężne maszyny wykorzystujące architekturę procesorów POWER (ppc64), zaprojektowaną z myślą o ekstremalnej wydajności. Jednostki te oferują wielowątkowość na poziomie SMT8, co oznacza, że jeden fizyczny rdzeń obsługuje osiem wątków jednocześnie. Całością zarządza wbudowany w firmware hypervisor PowerVM, który poprzez konsolę HMC pozwala dzielić fizyczny serwer na logiczne partycje LPAR, izolując od siebie systemy operacyjne.
Właśnie tutaj dochodzimy do punktu, który jest dla tej platformy jednocześnie największą zaletą i najcięższym brzemieniem. Ze względu na tak głęboką integrację z dedykowanym i kosztownym sprzętem, IBM i jest systemem elitarnym, w tym mniej pozytywnym znaczeniu. Zwykły śmiertelnik, student informatyki czy entuzjasta jak Ja czy Ty, nie ma szansy „dotknąć” tego systemu w domowym zaciszu. Nie pobierzesz obrazu ISO z internetu, nie zainstalujesz go na wirtualnej maszynie w VirtualBox, i nie uruchomisz na swoim laptopie. Bariera wejścia jest ustawiona na poziomie ceny serwera IBM Power, co skutecznie odcina dopływ „świeżej krwi” i sprawia, że wiedza o tej fascynującej architekturze jest przekazywana niemal jak wiedza cechowa, tylko wewnątrz dużych organizacji.
Rozdział 2: Interfejsy
Terminal 5250 (Zielone Ekrany)
Skoro wiemy już, że system jest potężny i znamy już jego fundamenty, musimy zmierzyć się z jego wizytówką “wizualną”, w tym miejscu również ten system nie przestaje zaskakiwać, słynnym „Green Screenem”. Choć dla postronnych wygląda on jak relikt przeszłości, dla administratorów interfejs tekstowy 5250 pozostaje wzorem ergonomii i szybkości. Tutaj nie tracimy czasu na szukanie ikon myszką, bo praca opiera się na pamięci mięśniowej i kilku kluczowych skrótach. Klawisz F1 to nie atrapa znana z Windowsa, ale potężna pomoc kontekstowa, która potrafi wytłumaczyć każdy błąd. F3 i F12 służą do nawigacji, przy czym ten pierwszy definitywnie zamyka program, a drugi pozwala bezpiecznie cofnąć się o krok.
Największą magią jest jednak klawisz F4. To genialny mechanizm podpowiedzi, który sprawia, że nie musisz pamiętać skomplikowanej składni komend. Wystarczy wpisać polecenie i wcisnąć F4, a system sam wyświetli formularz do uzupełnienia parametrów. Dzięki temu praca w terminalu jest błyskawiczna, a w razie zagubienia komenda GO MAIN zawsze bezpiecznie wrzuci nas z powrotem do menu głównego.
Na koniec mamy klawisze funkcyjne powyżej F12 ich używanie zawsze budzi uśmiech osób które systemu nie widziały wcześniej na oczy. Zastanawiają się jak użyć F14 na klawiaturze PC. sprawa jest prosta robimy to z klawiszem SHIFT i wtedy taki SHIFT+F2 staje się F14. Każdy różnie sobie to wizualizuje, aby sprawnie wybijać na klawiaturze Fki powyżej F12, jedną z metod jest wyobrażenie sobie zegara i godzin na tarczy godzina druga to czternasta i tak samo jest na naszej klawiaturze komputera. Używanie tych wysokich klawiszy F wynika z historycznej konstrukcji klawiatury terminala 5250 która miała dwa rzędy takich klawiszy.
Navigator for i: Interfejs webowy systemu
IBM i nie ignoruje jednak współczesnych standardów. Dostępna przez przeglądarkę konsola IBM Navigator for i stanowi kluczowe uzupełnienie dla terminala, choć rzadko udaje mu się go zastąpić. Administratorzy sięgają po nią w specyficznych scenariuszach, gdzie interfejs graficzny zyskuje naturalną przewagę nad tekstem. Wizualna natura Navigatora sprawdza się idealnie przy intuicyjnym zarządzaniu plikami, konfiguracji sieci czy graficznym podglądzie aktywnych zadań. Prawdziwą perłą w koronie tego narzędzia jest jednak PDI, czyli Performance Data Investigator. To potężny moduł, który zamienia surowe dane systemowe w czytelną opowieść o stanie maszyny. Zamiast analizować niekończące się kolumny cyfr, administrator otrzymuje interaktywne wykresy użycia procesora, pamięci czy dysków w czasie, co pozwala namierzać wąskie gardła w aplikacjach z chirurgiczną precyzją, często niemożliwą do osiągnięcia przy tradycyjnym przeglądaniu logów.
Control Language (CL)
Skoro zalogowaliśmy sie do systemu, musimy poznać język, w jakim wydaje się mu polecenia. W świecie IBM i nie jest to zlepek przypadkowych skrótów, lecz przemyślana, inżynierska konstrukcja zwana Control Language (CL). To coś więcej niż powłoka systemowa; to spoiwo łączące administratora z systemem.
Siła CL tkwi w jego genialnej, niemal gramatycznej składni opartej na schemacie Czasownik-Rzeczownik (Verb-Noun). W przeciwieństwie do systemów Unix, gdzie komendy bywają kryptograficznymi zagadkami (jak ls, grep czy awk), tutaj nazwy poleceń są logicznymi zdaniami skróconymi do trzech liter. Jeśli chcesz z czymś pracować, używasz przedrostka WRK (Work with). Jeśli chcesz coś stworzyć, piszesz CRT (Create), a gdy chcesz to usunąć, DLT (Delete). Wyświetlanie to DSP (Display), a zmiana to CHG (Change).

Ta przewidywalność sprawia, że nawet nie znając dokładnej nazwy komendy, można ją wydedukować. Chcesz zarządzać aktywnymi zadaniami? Składasz „pracuj” (WRK), „aktywne” (ACT) i „zadania” (JOB), otrzymując jedną z najczęściej używanych komend: WRKACTJOB. Chcesz utworzyć profil użytkownika? CRTUSRPRF. Usunąć plik? DLTF. To logiczna układanka, która drastycznie skraca czas nauki systemu. Co więcej, komendy te nie muszą być wpisywane ręcznie za każdym razem. Można je zamykać w programy CL (*PGM typu CLP lub CLLE). Służą one do automatyzacji powtarzalnych procesów, ustawiania odpowiedniej listy bibliotek (LIBL) przed uruchomieniem aplikacji czy sterowania przepływem danych między modułami.
Wartości Systemowe (System Values)
Na samym szczycie drabiny zarządzania, ponad zwykłymi komendami, stoi jednak „konstytucja” całej maszyny. Są to Wartości Systemowe (globalne parametry), swego rodzaju cyfrowe DNA, które definiuje zachowanie systemu operacyjnego na najniższym poziomie. Nie edytuje się ich w plikach tekstowych, lecz zarządza centralnie poprzez komendę WRKSYSVAL. To tutaj zapadają decyzje o fundamentalnych kwestiach bezpieczeństwa i kultury pracy serwera.
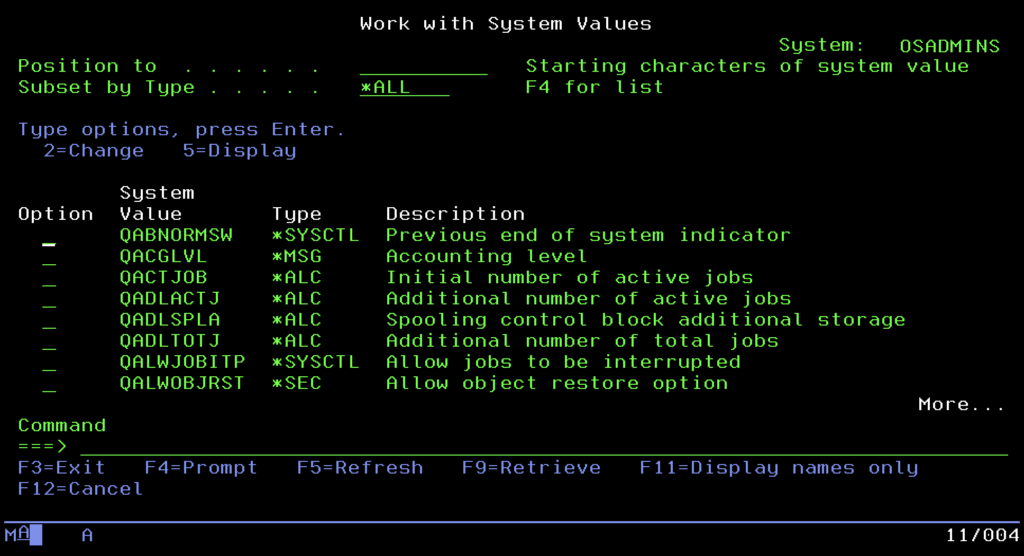
Administratorzy ze szczególną uwagą traktują wartość QSECURITY, która decyduje o tym, czy system jest otwartą twierdzą, czy bezpiecznym bunkrem spełniającym rygorystyczne normy bankowe (poziom 40 lub 50 – Integrity Protection). Równie istotny jest parametr QPWDVLDPGM, pozwalający podpiąć zewnętrzny program walidujący hasła i wymuszający politykę ich złożoności, czy prozaiczny QDATFMT, ustalający format daty. Warto też wspomnieć o QSTRUPPGM, kluczowej wartości wskazującej program, który ma się uruchomić automatycznie po starcie systemu. To właśnie w tym miejscu definiuje się, jakie podsystemy, bazy danych i serwery aplikacyjne mają uruchomić się wraz z maszyną, co pozwala na pełną automatyzację sekwencji startowej całego środowiska.
Struktura obiektów i bibliotek
Aby w pełni zrozumieć, jak ten system porządkuje rzeczywistość, musimy na chwilę zapomnieć o gąszczu nieskończenie zagnieżdżonych folderów, do których przyzwyczaiły nas Windows czy Linux. Natywny świat IBM i stawia na rygorystyczną, niemal płaską hierarchię, która wymusza na administratorach i programistach niezwykłą dyscyplinę.
Na szczycie tej struktury stoi absolutny władca, biblioteka systemowa QSYS. To swoista „matka” wszystkich zasobów i jednocześnie jedyny wyjątek od reguły, który za chwilę wyjaśnię. QSYS jest korzeniem systemu i w swoim wnętrzu przechowuje kluczowe elementy sterujące maszyną: profile użytkowników, definicje urządzeń oraz, co najważniejsze , wszystkie inne biblioteki.
I tu dochodzimy do żelaznej zasady architektury IBM i: zwykła biblioteka (oznaczana typem *LIB) nie może zawierać innej biblioteki. Zapomnijcie o tworzeniu skomplikowanych drzew podkatalogów typu „2024/styczeń/faktury”. Poza unikalnym przypadkiem QSYS która zawiera w sobie inne bibloteki, struktura jest zawsze jednopoziomowa. Biblioteka użytkownika to logiczny kontener, worek na obiekty (programy i dane), który leży bezpośrednio pod QSYS, ale sam w sobie nie może mieć już „dzieci” w postaci kolejnych bibliotek.
Obok obszarów tworzonych przez nas dla aplikacji, w systemie zawsze obecne są kontenery dostarczone przez IBM, takie jak QGPL (General Purpose Library) służąca do przechowywania obiektów tymczasowych i ogólnych, czy QUSRSYS, magazynująca informacje specyficzne dla konfiguracji danego serwera.
Ta specyficzna, „płaska” architektura determinuje sposób, w jaki odwołujemy się do danych. Adresowanie jest tu niezwykle eleganckie w swojej prostocie i opiera się na schemacie BIBLIOTEKA/OBIEKT. Jeśli więc szukasz konkretnej tabeli z fakturami w swojej aplikacji, system nie każe ci błądzić po długich ścieżkach dostępu, lecz prowadzi prosto do celu adresem w formacie MYAPP/FAKTURY. Taki model sprawia, że znalezienie dowolnego zasobu w systemie jest błyskawiczne, a bałagan, o ile trzymamy się zasad, trudny do zrobienia.
Library List (*LIBL)
Skoro wiemy już, jak adresować obiekty, pojawia się naturalne pytanie: czy za każdym razem musimy podawać ich pełną, sztywną ścieżkę w formacie BIBLIOTEKA/OBIEKT? Byłoby to uciążliwe i mało elastyczne. Tutaj na scenę wkracza lista bibliotek, znana jako Library List (*LIBL).
Można o niej myśleć jak o znacznie bardziej zaawansowanym odpowiedniku zmiennej %PATH% z Windows czy $PATH z systemów Unix. Jest to uporządkowana lista miejsc, które system przeszukuje automatycznie, gdy wywołujemy program lub otwieramy plik bez wskazywania jego konkretnego adresu. Kolejność ma tu kluczowe znaczenie. System zawsze zaczyna poszukiwania od części systemowej (gdzie znajdują się narzędzia IBM), następnie zagląda do tzw. biblioteki bieżącej (Current Library), a na końcu skanuje część użytkownika, gdzie rezydują nasze aplikacje.
Na przykład w procesie wytwarzania oprogramowania. Wyobraźmy sobie sytuację, w której programista musi przetestować nową wersję programu CALC. Zamiast modyfikować kod lub kopiować pliki, wystarczy, że zmodyfikuje swoją listę bibliotek, umieszczając bibliotekę testową TESTLIB przed produkcyjną PRODLIB. Kiedy teraz wywoła komendę CALC, system „chwyci” pierwszą napotkaną wersję, tę testową. Reszta firmy, pracująca na standardowej liście, wciąż będzie używać wersji produkcyjnej. To pozwala na bezkolizyjne testowanie zmian na żywym organizmie, bez konieczności fizycznego podmieniania plików wykonywalnych.
Na koniec bibloteka QTEMP to unikalne rozwiązanie IBM dla danych roboczych, które izoluje procesy poprzez tworzenie unikalnej instancji biblioteki dla każdego zalogowanego użytkownika lub zadania. Dzięki temu użytkownicy mogą bezpiecznie tworzyć tymczasowe tabele, pliki i eksperymentalne kopie danych, nie obawiając się konfliktów z innymi. Największą zaletą QTEMP jest automatyczne czyszczenie: biblioteka i jej zawartość znikają natychmiast po zakończeniu sesji lub zadania, eliminując potrzebę ręcznego usuwania plików tymczasowych. To system dba o „higienę pracy”, zapewniając, że po wyjściu z „biura” twoje „biurko” jest zawsze czyste.
Db2 for i: Serce systemu
Dochodzimy wreszcie do elementu, który definiuje tożsamość całej platformy i stanowi o jej unikalności na tle rynkowej konkurencji. W świecie Windows czy Linux przywykliśmy, że baza danych jest po prostu kolejną aplikacją, którą trzeba kupić, zainstalować i skonfigurować na wierzchu systemu operacyjnego. W IBM i sytuacja wygląda zupełnie inaczej: tutaj baza danych nie jest nakładką, lecz integralną częścią licencjonowanego kodu wewnętrznego (LIC). Db2 for i jest nierozerwalnie połączona z jądrem systemu, co oznacza, że nie można jej wyłączyć ani odinstalować. Jest ona naturalnym środowiskiem życia dla wszystkich danych, korzystającym z tych samych mechanizmów zarządzania pamięcią i bezpieczeństwem co sam system operacyjny.
Aby zrozumieć ten fenomen, musimy spojrzeć na ewolucję sposobów opisu danych. Przez dekady, zanim SQL stał się uniwersalnym standardem, w świecie IBM i królował DDS (Data Description Specifications). Warto tu wyjaśnić fundamentalną różnicę: DDS nie jest językiem zapytań służącym do „rozmowy” z bazą, tak jak robimy to dzisiaj instrukcją SELECT. To surowy, pozycyjny język definicji struktury, swoisty architektoniczny plan. Programista nie pisał w nim zapytań, lecz w sztywnych kolumnach kodu źródłowego mozolnie definiował, że od pierwszego do dziesiątego bajtu znajduje się „Nazwisko”, a kolejne cztery bajty to „Data”. Następnie taki plik musiał zostać skompilowany, aby system utworzył na dysku obiekt.
W ten sposób powstawały dwa rodzaje bytów: Pliki Fizyczne (PF), będące rzeczywistymi kontenerami przechowującymi dane (odpowiednik tabel), oraz Pliki Logiczne (LF). Te drugie pełniły rolę sprytnych nakładek, nie zawierały danych, lecz jedynie instrukcje (indeksy), jak posortować lub przefiltrować dane z pliku fizycznego. Było to rozwiązanie niezwykle wydajne, ale hermetyczne i wymagające specyficznej wiedzy, dostępnej tylko dla inżynierów tej jednej platformy.
Współczesny świat należy jednak do SQL. Dlaczego teraz on dominuje? Ponieważ jest elastyczny, dynamiczny i zrozumiały dla każdego informatyka na świecie, pozwalając tworzyć i modyfikować struktury „w locie”, bez żmudnego procesu kompilacji. Jednak geniusz inżynierów z Rochester polegał na tym, że nie zastąpili starego nowym, lecz sprawili, że oba te światy stały się tożsame. Tabela SQL stworzona dzisiaj nowoczesnym skryptem CREATE TABLE jest dla systemu pod spodem po prostu Plikiem Fizycznym, a widok czy indeks to nic innego jak Plik Logiczny. Dzięki tej dwukierunkowej kompatybilności 30-letni program księgowy napisany w RPG, oparty na starym DDS, może natywnie pracować na tych samych tabelach, z których korzysta nowoczesna aplikacja webowa w Javie.
Ta dwoistość dotyczy również sposobu dostępu do informacji. Tradycyjne aplikacje często korzystają z tzw. Native I/O, czyli dostępu rekordowego, który pozwala programiście z chirurgiczną precyzją pobierać dane wiersz po wierszu. Jest to metoda niesamowicie szybka w specyficznych zastosowaniach transakcyjnych. Z drugiej strony, nowoczesne podejście opiera się na silniku SQL i jego optymalizatorze (SQE), który dzięki zaawansowanej statystyce sam decyduje, jak najszybciej wydobyć żądany zestaw danych. W IBM i oba te mechanizmy działają ramię w ramię, dając programistom wybór broni: precyzyjny skalpel Native I/O lub ciężką artylerię SQL.
Nad bezpieczeństwem tego wszystkiego czuwa mechanizm Kronikowania (Journaling), będący systemową „czarną skrzynką”. Każda operacja zmiany danych, wstawienie, aktualizacja czy usunięcie rekordu, jest najpierw zapisywana w dzienniku i jego odbiorniku, a dopiero potem fizycznie trafia do tabeli. To rozwiązanie pełni dwie krytyczne funkcje. Po pierwsze, umożliwia obsługę transakcji (Commitment Control), gwarantując, że skomplikowane operacje finansowe wykonają się w całości albo wcale. Po drugie, zapewnia niezawodne odzyskiwanie danych (Recovery). Jeśli w serwerowni nagle zabraknie prądu, system po restarcie automatycznie sięgnie do kroniki i odtworzy wszystkie zmiany, które znajdowały się w pamięci, a nie zdążyły zapisać się na dysku, co czyni utratę danych zjawiskiem niezwykle rzadkim.
Na koniec warto wyraźnie oddzielić Db2 for i od jej imienniczki z innych platform, czyli Db2 LUW (Linux, Unix, Windows). To nie są te same produkty. Wersja na IBM i jest bazą „bezobsługową”. Dzięki architekturze Single Level Storage administrator nie musi tutaj zarządzać plikami tabel, przestrzeniami dyskowymi czy buforami pamięci, jak ma to miejsce w Oracle czy SQL Serverze. Baza po prostu „jest”, automatycznie rozciągając się na całą dostępną przestrzeń dyskową, co pozwala odciążyć administratora z technikaliów strojenia silnika bazy danych.
Rozdział 3: Operacje
Work Management
Do tej pory skupiliśmy się na statycznej strukturze: obiektach, bibliotekach i bazie danych. Jednak nie możemy zapominać o tym co dało platformie jej pierwotną nazwę AS/400, czyli Application System. To nie jest tylko baza danych, to przede wszystkim potężny serwer aplikacji. Dzięki temu, że baza Db2 znajduje się tuż obok jądra, aplikacje biznesowe działają z niespotykaną prędkością, ale ta moc wymaga kontroli. Mechanizmy, które zaraz omówimy, służą właśnie do tego, aby w systemie panował idealny porządek, a zasoby procesora, pamięci trafiały tam, gdzie są najbardziej potrzebne.
Podstawową jednostką życia w tym systemie jest Job (Zadanie). Każda aktywność, od zalogowania użytkownika po nocne przeliczanie magazynu, jest Jobem. Można o nim myśleć jak o procesie znanym z systemów Unix (posiadającym PID), ale tutaj identyfikacja jest bardziej „ludzka”. Każdy Job posiada unikalną, trójczłonową sygnaturę w formacie: Numer/Użytkownik/Nazwa. Dzięki temu administrator widząc ciąg 123456/QUSER/QZDASOINIT, od razu wie, kto i co uruchomił, bez konieczności mapowania tajemniczych numerów PID na nazwy usług.
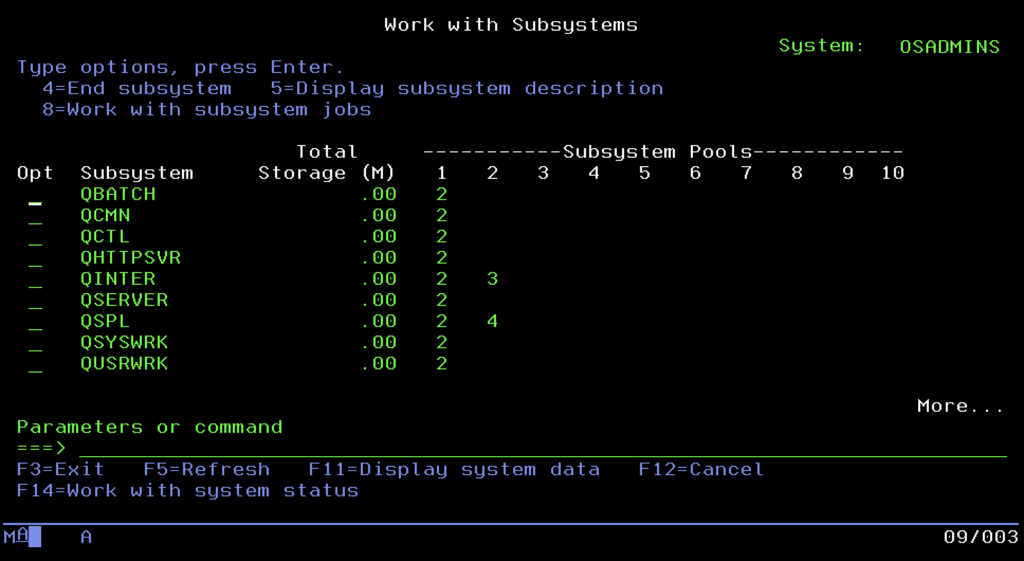
Świat zadań dzieli się na dwie główne sfery. Pierwsza to Interactive, czyli sesje użytkowników pracujących na terminalach 5250, wymagające natychmiastowej reakcji. Druga to Batch, potężne procesy przetwarzania wsadowego, które mielą dane w tle, zazwyczaj w nocy, nie wymagając interakcji z człowiekiem. Aby te dwa światy nie wchodziły sobie w drogę i aby jeden użytkownik generujący raport nie zablokował pracy całego biura, inżynierowie IBM wymyślili Subsystemy. Są to wirtualne kontenery, wydzielone strefy pamięci i procesora, w których uruchamiane są zadania. Zazwyczaj użytkownicy interaktywni trafiają do podsystemu QINTER, gdzie priorytetem jest czas reakcji, podczas gdy ciężkie zadania w tle lądują w QBATCH, gdzie są kolejkowane i przetwarzane jedno po drugim. Nad całością czuwa zazwyczaj podsystem sterujący QCTL, będący mózgiem operacyjnym maszyny.
Unikalną cechą IBM i jest również sposób, w jaki system „rozmawia” z otoczeniem, czyli Message Handling. W przeciwieństwie do systemów Linux Unix Windows, które po prostu wyrzucają błędy do tekstowych logów i „umierają” , ten system prowadzi dialog i w takiej sytuacji wysyła Ci informację. Komunikacja odbywa się poprzez Kolejki Komunikatów (*MSGQ). Najważniejszą z nich jest QSYSOPR (główna konsola operatora). To tam trafiają informacje o awariach dysków czy problemach z backupem.
Najciekawszy jest jednak mechanizm interakcji z błędami aplikacji. Wyobraźmy sobie sytuację, w której program księgowy natrafia na problem, może to być brak papieru w drukarce, zablokowany rekord w bazie danych albo nagły brak uprawnień do konkretnego obiektu. Zamiast się wyłączyć (crash), jak to ma miejsce w większości współczesnych środowisk, program na IBM i wysyła komunikat typu Inquiry (Pytanie) i wchodzi w specyficzny stan MSGW (Message Wait). W tym momencie zadanie zamarza i czeka. System nie zabija procesu, lecz cierpliwie oczekuje na decyzję administratora.
Jest to właściwość wybitnie przydatna, wręcz zbawienna w krytycznych środowiskach produkcyjnych. Aby docenić geniusz tego rozwiązania, wyobraźmy sobie proces nocnego przetwarzania, który trwa dwie godziny. W 119. minucie występuje błąd. W świecie klasycznych systemów operacyjnych, takich jak Linux, Unix czy Windows, zazwyczaj oznacza to definitywny koniec. Proces „umiera”, a administrator staje przed koniecznością żmudnego szukania przyczyny w logach (o ile program był łaskaw je zostawić). Po naprawieniu usterki musi uruchomić zadanie od nowa i czekać kolejne dwie godziny „z duszą na ramieniu”, mając nadzieję, że tym razem wszystko zakończy się sukcesem.
W przypadku IBM i scenariusz ten wygląda zupełnie inaczej. Gdy proces wchodzi w stan MSGW, dostajemy jasny komunikat na konsolę operatora: „Brak uprawnień do pliku X”. Czas dla tego zadania się zatrzymuje. Administrator może spokojnie przeanalizować problem, nadać brakujące uprawnienia „w locie”, a następnie odpowiedzieć na komunikat poleceniem „Ponów próbę” (Retry). System wznowi przetwarzanie dokładnie w tym milisekundowym punkcie, w którym zostało ono wstrzymane. Zamiast straconych dwóch godzin i restartu całego procesu, mamy jedynie kilkuminutową pauzę operacyjną. Stan MSGW to jasny sygnał od maszyny: „żyję, pamiętam co robiłam i czekam na twoją pomoc, by dokończyć pracę”.
Integrated File System i Open Source
Kilka chwil temu starałem się wykorzenić z głowy przyzwyczajenia ze świata Windows i Linux, powtarzając jak mantrę, że w IBM i „wszystko jest obiektem”, a pojęcie pliku w klasycznym rozumieniu nie istnieje. I teraz, dość przewrotnie, muszę wykonać woltę i powiedzieć: to nie do końca prawda. Witajcie w Integrated File System (IFS), miejscu, gdzie IBM i podaje rękę reszcie informatycznego świata.
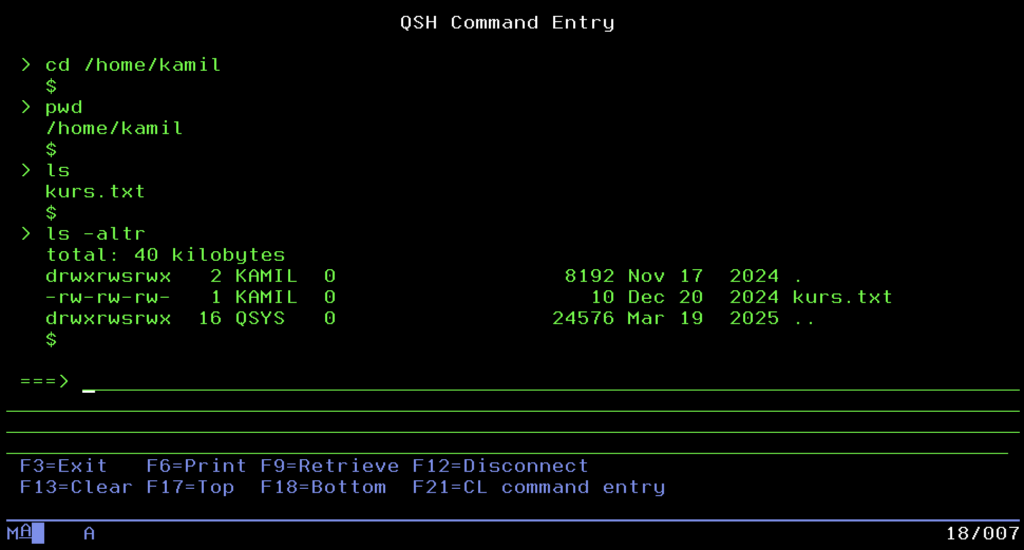
Inżynierowie IBM wiedzieli, że izolacja prowadzi donikąd. Aby system mógł komunikować się z otoczeniem i obsługiwać nowoczesne technologie webowe, musiał „nauczyć się” standardów POSIX. Tak powstał IFS. To nic innego jak wbudowany w system mechanizm, który emuluje klasyczną, drzewiastą strukturę katalogów, którą znamy z Unixa czy Windowsa. Zaczynamy od katalogu głównego (Root /) i schodzimy w dół, tworząc podfoldery takie jak /home/user/dokument.txt.
To właśnie tutaj, a nie w hermetycznych bibliotekach, ląduje wszystko to, co przyszło z „nowego świata”. Jeśli chcecie uruchomić aplikację w Node.js, postawić serwer WWW serwujący pliki HTML, odpalić skrypty PHP czy przechować pliki .jar dla maszyny wirtualnej Javy, zrobicie to właśnie w IFS. Co więcej, dla użytkownika komputera PC ten obszar jest najbardziej przyjazną częścią serwera. Dzięki obsłudze protokołu SMB, katalogi IFS można zmapować w systemie Windows jako zwykły dysk sieciowy. Możesz przeciągać i upuszczać pliki na potężny serwer enterprise, jakby to był zwykły pendrive, lub łączyć się z nim przez klientów SFTP czy nawet SSH.
Najciekawszy w tym wszystkim jest jednak fakt, że IFS działa jak wielki parasol, który przykrywa całą maszynę. I tu dochodzimy do sedna integracji: omawiany przez nas wcześniej „święty” świat obiektów i bibliotek (QSYS.LIB) nie jest oddzielnym bytem. Z perspektywy IFS jest on po prostu jednym z podkatalogów widocznym pod ścieżką /QSYS.LIB/. To genialna abstrakcja, która sprawia, że system plików jest jeden, ale ma wiele twarzy, w zależności od tego, czy potrzebujemy płaskiej struktury do szybkiego przetwarzania transakcji, czy drzewa katalogów do serwowania strony internetowej.
PASE
Samo przechowywanie plików to jednak za mało, by przyciągnąć nowoczesnych deweloperów. Dlatego IBM poszedł o krok dalej, tworząc PASE (Portable Application Solutions Environment). To nic innego jak kompletne środowisko uruchomieniowe systemu AIX (Unix od IBM), działające bezpośrednio wewnątrz IBM i. To nie jest powolna emulacja; to system operacyjny w systemie operacyjnym, korzystający bezpośrednio z jądra maszyny.
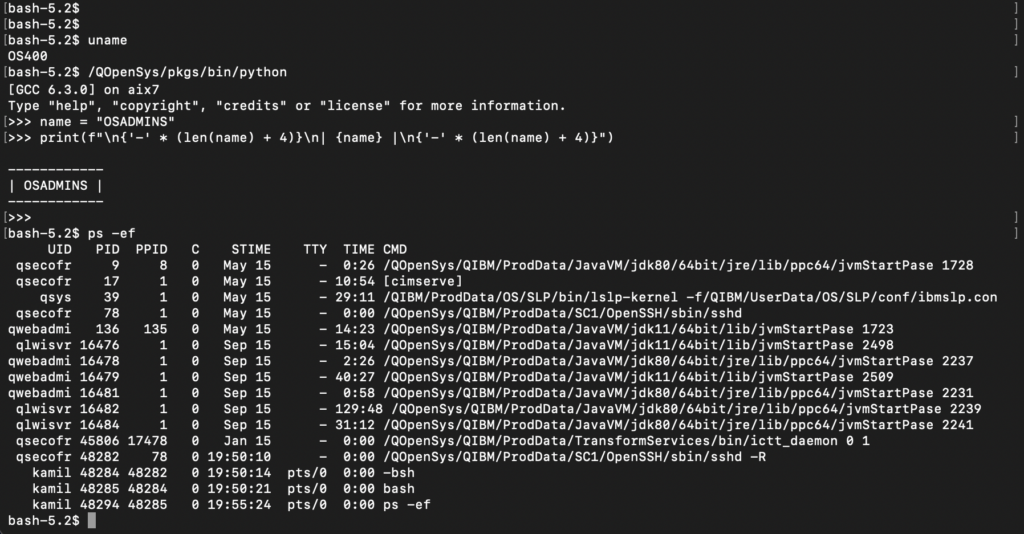
Dzięki PASE, „zielony ekran” zyskał nowe życie. Administratorzy i programiści mogą uruchomić powłokę Bash, korzystać z systemu kontroli wersji Git, pisać skrypty w Pythonie czy uruchamiać serwery w Node.js. To, co kiedyś wydawało się niemożliwe na maszynie „księgowej”, dziś jest standardem. Zarządzanie tym inwentarzem odbywa się w sposób znany każdemu użytkownikowi Linuxa (Red Hat/CentOS), za pomocą menedżera pakietów Yum (zarządzającego pakietami RPM). Oznacza to, że IBM i stał się platformą hybrydową w pełnym tego słowa znaczeniu: potrafi jednocześnie przetwarzać miliony transakcji bankowych w starym RPG i serwować nowoczesne API, korzystając z tych samych danych i zasobów.
Zarządzanie cyklem życia i aktualizacje systemu
Skoro mamy już uruchomione aplikacje, bazę danych i nowoczesne usługi, musimy zadbać o to, by system trwał. W świecie IBM i stabilność nie jest dziełem przypadku, lecz efektem porządku. Tutaj nie instaluje się przypadkowych plików ściągniętych z internetu. Wszystko, co trafia do jądra systemu, musi przejść przez sformalizowany proces inwentaryzacji. Centrum dowodzenia tym procesem jest menu dostępne po wpisaniu komendy GO LICPGM. Nie jest to żadne magiczne zaklęcie, w nomenklaturze tego systemu GO oznacza po prostu przejście do menu, a LICPGM to skrót od Licensed Programs.
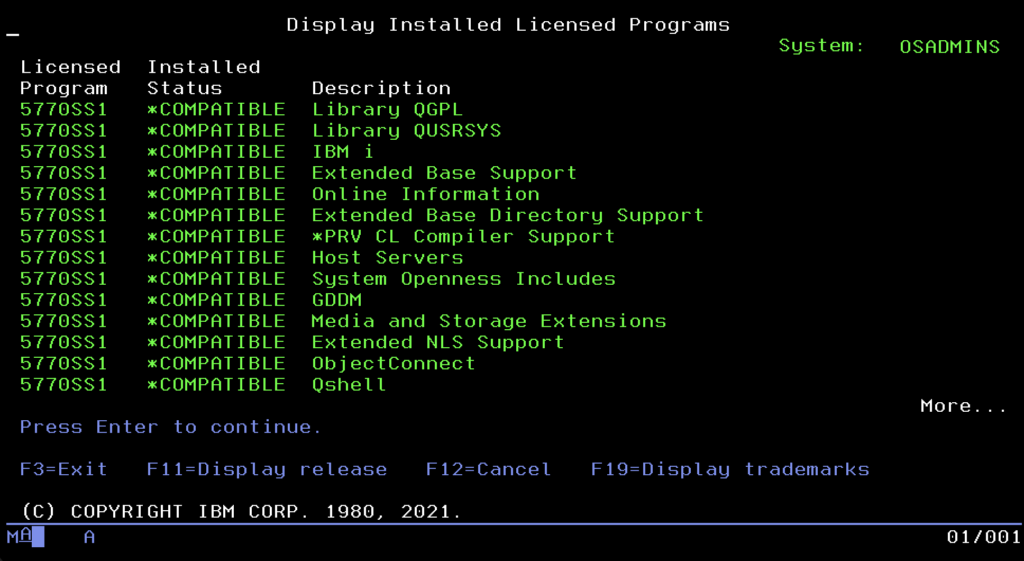
Można o tym myśleć jak o systemowym „sklepie z aplikacjami” lub panelu „Dodaj/Usuń programy”, tyle że w wersji tekstowej. To tutaj administrator widzi oprogramowanie zainstalowane na maszynie jako sformalizowane „produkty”. Menu to prowadzi użytkownika za rękę: wybierając odpowiednie opcje z listy, można zainstalować nowe funkcje, usunąć zbędne komponenty, by zwolnić miejsce, lub wyświetlić listę posiadanych licencji. To nakładka, która ukrywa przed nami skomplikowane komendy instalacyjne, pozwalając zarządzać „wyposażeniem” serwera w uporządkowany sposób.
Kluczowe jest tu zrozumienie, co system uważa za „Licencjonowany Program”. Choć najczęściej w tym menu zobaczymy produkty dostarczone przez IBM, mechanizm ten jest otwarty również dla firm trzecich. Profesjonalni dostawcy oprogramowania (np. narzędzi do High Availability, systemów ERP czy rozwiązań bankowych) często pakują swoje aplikacje w ten sam standard (LPP – Licensed Program Product). Dzięki temu ich oprogramowanie staje się pełnoprawnym obywatelem systemu, widnieje na oficjalnej liście zainstalowanych produktów i może być instalowane oraz aktualizowane systemową komendą RSTLICPGM, zamiast ręcznego odtwarzania bibliotek. Co więcej, podlega ono tej samej systemowej weryfikacji spójności co komponenty dostarczone przez IBM. Wiele mniejszych aplikacji jest co prawda dystrybuowanych w prostszy sposób (jako zwykłe biblioteki), przez co nie widać ich w tym menu, ale „waga ciężka” oprogramowania zazwyczaj korzysta z dobrodziejstw LICPGM.
Narzędzie to posiada jeszcze jedną, genialną funkcję, działającą jak przegląd techniczny samochodu. Mowa o opcji CHKPRDOPT (Check Product Option). Pozwala ona przeskanować zainstalowane oprogramowanie (zarówno IBM, jak i to od zewnętrznych dostawców, jeśli jest odpowiednio zapakowane) i sprawdzić jego spójność. System weryfikuje, czy żaden plik nie został przypadkiem skasowany lub uszkodzony. Jeśli mechanizm wykryje jakąkolwiek nieprawidłowość w strukturze katalogów czy sumach kontrolnych plików, od razu o tym poinformuje. To daje administratorowi pewność, że „pod maską” wszystko gra, zanim jeszcze pojawią się pierwsze problemy z działaniem aplikacji.
Jednak nawet najlepiej zarządzany system wymaga łatania błędów. W świecie IBM i łatka nazywa się PTF (Program Temporary Fix). Choć nazwa sugeruje „tymczasowość”, w rzeczywistości są to trwałe poprawki kodu. IBM nie każe jednak administratorom instalować tysięcy pojedynczych plików. Poprawki grupowane są w pakiety. Raz na jakiś czas wydawany jest Cumulative Package, potężny zbiór wszystkich poprawek, swego rodzaju „Service Pack”. Dla specyficznych obszarów, takich jak baza danych czy serwer HTTP, istnieją mniejsze zbiory zwane Group PTF. Dzięki temu aktualizacja systemu przypomina bardziej wymianę całego modułu niż cerowanie dziur.
Prawdziwym majstersztykiem inżynierii jest jednak mechanizm Technology Refresh (TR). Dawniej, aby uzyskać obsługę nowego sprzętu lub nowe funkcje SQL, trzeba było robić pełny upgrade systemu operacyjnego do wyższej wersji. TR zmienił te zasady. To duże pakiety aktualizacji, które potrafią „wstrzyknąć” do działającego systemu nowe sterowniki sprzętowe np kart FC czy ETH, zmodernizować optymalizator zapytań czy dodać nowe instrukcje procesora, nie zmieniając numeru wersji systemu. Dzięki temu IBM i w wersji 7.4 po zainstalowaniu najnowszego TR potrafi rzeczy, o których w dniu jego premiery nikt nawet nie śnił.
Na koniec warto znać wersjonowanie systemu. Opiera się ono na schemacie V.R.M (Version, Release, Modification), np. V7R5M0. Nowe duże wydania pojawiają się rzadziej niż w świecie konsumenckim, zazwyczaj co 2-3 lata, ale żyją znacznie dłużej. Każda wersja posiada standardowy okres wsparcia wynoszący zazwyczaj około 7 lat. Warto jednak pamiętać, że oprogramowanie jest tu ściśle sprzężone ze sprzętem. Nowe wersje OS wymagają odpowiedniej mocy obliczeniowej, przykładowo IBM i 7.5 wymaga serwerów opartych na procesorach POWER9 lub POWER10. To symbioza, która wymusza na organizacjach ciągły, choć powolny i przewidywalny rozwój infrastruktury.
Użytkownicy i bezpieczeństwo
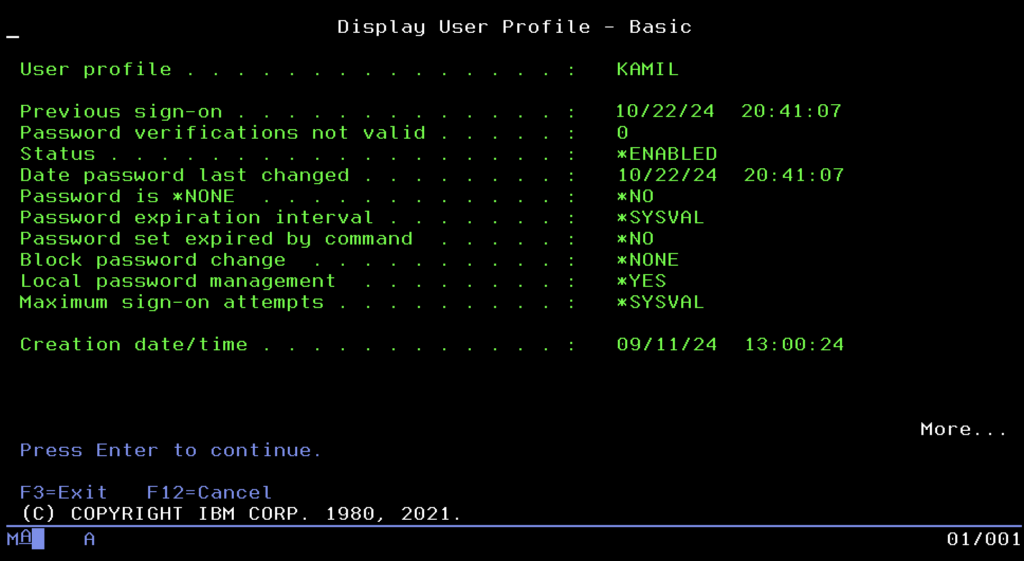
W świecie cyberbezpieczeństwa, gdzie każdego dnia słyszymy o wyciekach danych i atakach ransomware, IBM i cieszy się opinią cyfrowej twierdzy. Nie jest to jednak zasługa magii, lecz fundamentalnej architektury, o której mówiliśmy od początku. Ponieważ wirusy i złośliwe oprogramowanie są zazwyczaj pisane pod systemy operujące na plikach, w zderzeniu z hermetycznym światem obiektów IBM i często są bezradne, bo po prostu nie wiedzą, jak „zainfekować” bazę danych, która nie jest plikiem. Jednak ta naturalna odporność to tylko pierwsza linia obrony. Prawdziwe bezpieczeństwo zaczyna się od precyzyjnej kontroli dostępu, której fundamentem jest Profil Użytkownika.
W IBM i konto użytkownika to coś więcej niż login i hasło; to obiekt systemowy definiujący cyfrową tożsamość człowieka lub procesu w najdrobniejszych szczegółach. Zarządzanie tymi tożsamościami odbywa się w jednym miejscu, dostępnym pod komendą WRKUSRPRF. Można myśleć o tym narzędziu jak o systemowym panelu HR, gdzie administrator widzi listę wszystkich osób mających dostęp do maszyny. Wchodząc w edycję profilu, nie edytujemy pliku tekstowego, lecz ustawiamy parametry obiektu, korzystając często z gotowych szablonów zwanych Klasami Użytkowników. Najpopularniejszą z nich jest klasa *USER, przeznaczona dla zwykłych pracowników, którzy widzą tylko swoje aplikacje. Programiści otrzymują zazwyczaj klasę *PGMR, dającą dostęp do kompilatorów, natomiast pełnię władzy dzierży administrator z klasą *SECOFR, czyli Security Officer.
Klasa użytkownika to jednak tylko wstęp, ponieważ prawdziwą władzę w systemie definiują Uprawnienia Specjalne. Są to konkretne „supermoce”, które administrator może nadać wybranym profilom. Najważniejszym i najniebezpieczniejszym z nich jest *ALLOBJ (All Object), działające jak uniwersalny klucz do wszystkich drzwi. Użytkownik z tą flagą to odpowiednik „roota” w Uniksie, ma nieograniczony dostęp do absolutnie każdego obiektu w systemie i może skasować każdą bazę danych, nawet jeśli system teoretycznie mu tego zabroni. Innym istotnym uprawnieniem jest *JOBCTL (Job Control), dające władzę nad „fabryką”, czyli możliwość zarządzania cudzymi procesami, oraz *SPLCTL (Spool Control), które pozwala podglądać i kasować wydruki dowolnego pracownika w firmie, nawet te poufne.
Poza ogólnymi uprawnieniami system pozwala na niezwykle precyzyjną autoryzację na poziomie pojedynczych obiektów. Możemy skonfigurować środowisko tak, by jeden pracownik mógł tylko czytać dane z tabeli, inny mógł je zmieniać, a reszta firmy w ogóle nie widziała jej istnienia. Tu dochodzimy do najgenialniejszego mechanizmu tej platformy, zwanego Adopted Authority, czyli autoryzacją adoptowaną. Rozwiązuje on odwieczny problem: jak pozwolić księgowej na pracę w systemie finansowym, nie dając jej prawa do „grzebania” w bazie danych np. przez Excela. Dzięki temu mechanizmowi, gdy użytkowniczka uruchamia oficjalny program księgowy, na czas jego działania system „pożycza” jej uprawnienia właściciela programu. Działa to jak magiczny płaszcz, dopóki znajduje się wewnątrz bezpiecznej aplikacji, ma moc edycji bazy. W momencie wyjścia z programu uprawnienia znikają, a próba bezpośredniego dostępu do danych kończy się odmową.
Na samym szczycie tej piramidy uprawnień stoi jeden, konkretny profil, dostarczany fabrycznie wraz z systemem, QSECOFR (Security Officer). To absolutny władca maszyny, odpowiednik konta „root” w systemach Linux czy „Administrator” w Windows, ale z jeszcze głębszą integracją. QSECOFR posiada domyślnie wszystkie możliwe uprawnienia specjalne, w tym *ALLOBJ, co oznacza, że dla niego nie istnieją żadne zakazy ani blokady. To właśnie tego konta używa się do pierwszej konfiguracji serwera, instalacji systemu operacyjnego czy ratowania maszyny w sytuacjach krytycznych. Ze względu na jego potęgę, dobrą praktyką jest, by na co dzień „leżało ono w sejfie”, administratorzy powinni pracować na własnych, imiennych kontach, a po QSECOFR sięgać tylko w ostateczności. Utrata hasła do tego profilu jest jednym z niewielu scenariuszy, które mogą zmusić do reinstalacji całego systemu.
Backup i Restore
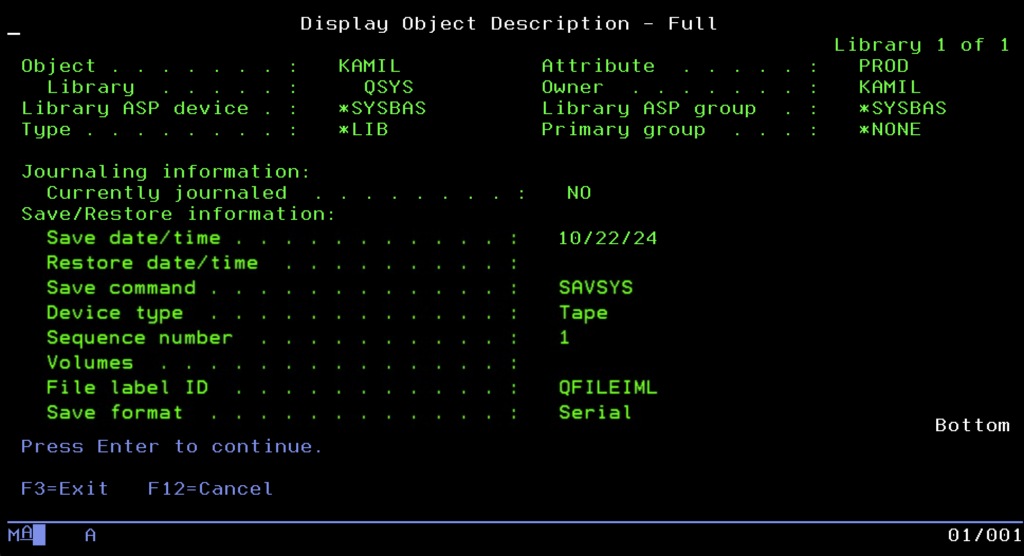
Nawet najlepiej zabezpieczona twierdza z najbardziej rygorystyczną kontrolą dostępu jest bezużyteczna, jeśli nie posiada kopii zapasowej. W świecie IBM i podejście do backupu jest tak samo zintegrowane jak reszta systemu, opierając się na strategii, w której odzyskiwalność danych jest priorytetem absolutnym. Na najniższym poziomie system oferuje zestaw natywnych komend, które pozwalają administratorowi „chirurgicznie” wyjmować i zapisywać fragmenty danych. Podstawowymi narzędziami są tu polecenia rozpoczynające się od prefiksu SAV, takie jak SAVLIB dla bibliotek czy SAVOBJ dla pojedynczych obiektów. Co niezwykle istotne, każdy obiekt w tym systemie posiada własną „pamięć” o kopiach zapasowych. Jeśli podejrzymy jego opis, znajdziemy tam precyzyjną informację o dacie ostatniego składowania oraz identyfikator woluminu (taśmy), na który trafił. Dzięki temu administrator, patrząc na sam obiekt, wie dokładnie, gdzie szukać jego kopii, bez konieczności przekopywania zewnętrznych rejestrów.
Dla ułatwienia pracy IBM przygotował gotowe scenariusze dostępne w menu GO SAVE. Najsłynniejszą pozycją jest tam Opcja 21, „przyciskiem atomowym”, która wykonuje zrzut absolutnie wszystkiego. Jednak w tym menu znajdują się również bardziej precyzyjne opcje. Administratorzy mogą skorzystać z opcji dedykowanych wyłącznie do składowania danych systemowych (Opcja 22) lub tylko danych użytkownika (Opcja 23). Jest to kluczowe, ponieważ pełny backup systemu (Opcja 21) wymaga wprowadzenia maszyny w stan restrykcyjny (Restricted State), co wiąże się z całkowitym odcięciem użytkowników i zatrzymaniem aplikacji. W dużych środowiskach korporacyjnych, działających w trybie 24/7, na taki luksus przestoju można pozwolić sobie rzadko. Dlatego na co dzień stosuje się strategie pozwalające na backup „na żywo”, wykorzystując mechanizm Save While Active, który gwarantuje spójność danych nawet przy otwartych plikach, lub wykonuje się kopie na zapasowym serwerze, na który dane są replikowane w czasie rzeczywistym.
Zarządzanie setkami taśm i skomplikowanym harmonogramem byłoby jednak koszmarem przy użyciu samych prostych komend, dlatego standardem w profesjonalnych środowiskach jest BRMS (Backup, Recovery and Media Services). To nie jest prosta nakładka, lecz potężny, pełnoprawny system zarządzania cyklem życia danych. W BRMS administrator nie myśli o pojedynczych komendach, lecz definiuje polityki backupu: co ma być składowane, w jakie dni, ile kopii ma powstać i jak długo mają być przechowywane (retencja). System sam pilnuje, kiedy taśma może zostać nadpisana, a kiedy musi być chroniona przed skasowaniem. Wszystkie te dane trafiają fizycznie na różne nośniki,od klasycznych taśm LTO czy biblioteki wirtualne (VTL). Ciekawostką są też obiekty typu *SAVF (Save File), które pozwalają zrobić backup do pliku na dysku, co idealnie sprawdza się przy przesyłaniu danych między serwerami przez sieć.
Monitoring i Diagnostyka
Administrator IBM i nie musi zgadywać, co dzieje się we wnętrzu maszyny; system ten został zaprojektowany tak, by dostarczać szczegółowych danych telemetrycznych na każdym poziomie działania. Pierwszym miejscem, do którego zagląda się, by sprawdzić ogólną kondycję serwera, jest ekran wywoływany komendą WRKSYSSTS (Work with System Status). To systemowy kardiomonitor. Choć widać tu bieżące użycie procesora, wzrok doświadczonego inżyniera wędruje zazwyczaj w dwa inne miejsca. Po pierwsze na wskaźnik % ASP Used, czyli procentowe zapełnienie dysków. W architekturze Single Level Storage przekroczenie progu 90% może drastycznie wpłynąć na wydajność, a całkowite zapełnienie zatrzyma maszynę. Po drugie, analizuje się wskaźnik błędów stronicowania (Faults) w pulach pamięci, co pozwala ocenić, czy system nie dławi się z braku RAM-u i nie traci czasu na żonglowanie danymi między dyskiem a pamięcią operacyjną.
Jeśli ogólne wskaźniki są w normie, ale system wydaje się powolny, sięgamy po „szkło powiększające”, czyli komendę WRKACTJOB (Work with Active Jobs). To odpowiednik Menedżera Zadań, który pokazuje listę wszystkich uruchomionych procesów. Możemy tu błyskawicznie posortować zadania według zużycia procesora, by znaleźć winowajcę, który „zjada” zasoby. To również tutaj najszybciej wyłapiemy zadania o statusie MSGW (Message Wait), procesy, które zatrzymały się i czekają na interwencję człowieka, na przykład z powodu błędu w programie lub braku papieru w drukarce.
Gdy coś idzie nie tak, system zazwyczaj głośno o tym informuje. Głównym kanałem komunikacji jest kolejka QSYSOPR, do której trafiają wszystkie krytyczne zdarzenia, od awarii sprzętowych po prośby o włożenie nowej taśmy do napędu. Jeśli jednak problem dotyczy konkretnej aplikacji, najcenniejszym źródłem wiedzy jest Job Log. Każde zadanie w systemie prowadzi swój własny, szczegółowy dziennik, który jest swoistą czarną skrzynką. Znajdziemy w nim zapis każdej wykonanej komendy i każdego błędu, co stanowi fundament debugowania i pozwala odtworzyć sekwencję zdarzeń prowadzącą do awarii.
Warto jednak zauważyć, że IBM i ewoluuje, a wraz z nim metody diagnostyki. Choć klasyczne komendy CL są wciąż w użyciu, nowoczesny administrator coraz częściej sięga po IBM i Services. To genialna koncepcja, która pozwala odpytywać system operacyjny tak, jakby był bazą danych. Zamiast wpisywać WRKSYSSTS, można wykonać zapytanie SQL: SELECT * FROM QSYS2.SYSTEM_STATUS. Pozwala to na łatwe tworzenie własnych raportów, dashboardów czy skryptów monitorujących, które automatycznie powiadomią nas o problemach, używając standardowego języka SQL.
Dla tych, którzy muszą spojrzeć wstecz i przeanalizować wydajność historyczną, system oferuje potężne narzędzia Performance Tools. Tradycjonaliści mogą korzystać z tekstowego menu GO PERFORM, ale prawdziwą rewolucją jest PDI (Performance Data Investigator) narzędzie graficzne dostępne w przeglądarce internetowej (w pakiecie IBM Navigator for i). PDI potrafi przetrawić gigabajty danych zbieranych przez system w tle i wyrysować interaktywne wykresy, pokazujące dokładnie, co działo się z procesorem, dyskami czy pamięcią tydzień temu o godzinie 14:00, pozwalając na głęboką analizę trendów i wąskich gardeł.
Narzędzia Serwisowe i Proces IPL
Gdy schodzimy coraz głębiej w architekturę IBM i, docieramy do warstwy, która funkcjonuje „pod” systemem operacyjnym. To tutaj zarządza się surowym sprzętem, konfiguracją macierzy dyskowych i kodem wewnętrznym maszyny. IBM udostępnia do tego celu dwa bliźniacze zestawy narzędzi, różniące się momentem, w którym można z nich skorzystać. Pierwszym, używanym na co dzień przez administratorów, jest SST (System Service Tools). Dostępne bezpośrednio z poziomu działającego systemu po wpisaniu komendy STRSST, pozwalają zajrzeć w „bebechy” maszyny bez przerywania pracy użytkowników. To tutaj konfiguruje się zabezpieczenia dyskowe (RAID, mirroring) czy dodaje nowe jednostki do puli ASP. Tu również przegląda się kluczowe rejestry maszyny: PAL (Product Activity Log) z surowymi błędami sprzętowymi, SAL (Service Action Log), który przetwarza je na gotowe zadania dla serwisu, oraz LIC Logs, rejestrujące błędy wewnętrznego mikrokodu. Warto pamiętać, że dostęp do tych narzędzi jest chroniony osobnym zestawem identyfikatorów i haseł, niezależnym od standardowych profili użytkowników systemu operacyjnego.
Sytuacja zmienia się, gdy system operacyjny nie działa lub dopiero startuje. Wtedy do gry wchodzi DST (Dedicated Service Tools). Funkcjonalnie jest to niemal lustrzane odbicie SST, ale dostępne wyłącznie z poziomu głównej konsoli systemowej (HMC), w trybie dedykowanym. DST to deska ratunku i narzędzie pierwszej konfiguracji. Używa się go do inicjalizacji nowych, surowych dysków, zanim jeszcze powstanie na nich system plików, do zaawansowanej diagnostyki sprzętu, gdy system nie chce wstac, a także w sytuacjach krytycznych,na przykład do zresetowania hasła profilu QSECOFR, gdy zostanie ono zapomniane.
Dostęp do DST jest ściśle powiązany z procedurą startu systemu, która w świecie IBM nosi nazwę IPL (Initial Program Load). Proces ten może przebiegać w dwóch trybach, wybieranych fizycznie na panelu maszyny lub wirtualnie na konsoli HMC. Tryb Normal to standardowe uruchomienie, automat ładuje system operacyjny prosto do ekranu logowania. Tryb Manual to uruchomienie serwisowe, które zatrzymuje proces startu w środowisku DST. Daje to administratorowi czas na wprowadzenie zmian w konfiguracji sprzętowej, wgranie poprawek mikrokomputera lub odzyskanie uszkodzonych struktur danych, zanim system operacyjny przejmie pełną kontrolę i udostępni zasoby użytkownikom.
Unikalną cechą tej platformy, stanowiącą o jej legendarnej niezawodności, jest mechanizm podwójnego kodu wewnętrznego, znany jako Side A i Side B. Maszyna przechowuje dwie niezależne kopie swojego „firmware’u” (Licensed Internal Code). Standardowo system pracuje na Stronie B. Strona A pełni rolę nienaruszalnej kopii zapasowej. Mechanizm ten jest kluczowy podczas aktualizacji: nowe poprawki (PTF) i zmiany w kodzie wewnętrznym są aplikowane tymczasowo na stronę B. Jeśli po restarcie okaże się, że aktualizacja zawiera błąd i system nie wstaje, administrator może po prostu przełączyć bootowanie na stronę A, uruchamiając maszynę ze sprawdzonej, stabilnej wersji kodu. To rozwiązanie sprawia, że ryzyko „uceglenia” serwera po aktualizacji jest w świecie IBM i praktycznie wyeliminowane.
High Availability (HA)
Mimo że taśmy i system BRMS stanowią solidną polisę ubezpieczeniową, mają jedną zasadniczą wadę: czas odzyskiwania. W przypadku katastrofalnej awarii przywrócenie terabajtów danych może zająć wiele godzin, a nawet dni. W środowiskach krytycznych, gdzie biznes działa 24/7, stosuje się więc rozwiązania klasy High Availability (HA). Ich celem jest utrzymanie ciągłości działania poprzez posiadanie drugiej, bliźniaczej maszyny, gotowej przejąć ruch w zaledwie kilka minut.
Najpopularniejszym podejściem w tym świecie jest replikacja logiczna, realizowana przez oprogramowanie takie jak MIMIX (czy konkurencyjne Quick-EDD). Rozwiązania te wykorzystują wbudowany w system mechanizm dziennikowania (Journaling), „nasłuchując” zmian na maszynie produkcyjnej i w czasie rzeczywistym przesyłając je i odtwarzając na serwerze zapasowym.
Co niezwykle istotne, maszyna zapasowa w tym modelu nie stoi bezczynnie. Znajdująca się na niej baza danych jest w pełni dostępna, zazwyczaj w trybie tylko do odczytu (Read-Only). Daje to ogromną korzyść biznesową: można tam przekierować ciężkie procesy raportowe i analityczne (BI). Dzięki temu skomplikowane zapytania SQL przetwarzane są na maszynie zapasowej, nie obciążając serwera produkcyjnego, na którym w tym samym czasie odbywa się bieżąca, płynna obsługa klientów.
Alternatywnym podejściem jest rozwiązanie sprzętowo-systemowe od IBM, czyli PowerHA. Zamiast kopiować pojedyncze transakcje, wykorzystuje ono klastrowanie i technologię Independent ASP (IASP). W tym modelu dane znajdują się na niezależnej puli dyskowej, która w normalnym trybie jest podłączona do serwera głównego, a w razie awarii jest błyskawicznie „przepinana” i udostępniana serwerowi zapasowemu. Niezależnie od wybranej technologii, nadrzędnym celem jest zawsze możliwość wykonania tzw. Role Swap, czyli szybkiego i bezpiecznego przełączenia użytkowników na zapasową infrastrukturę w sytuacji krytycznej.
Zakończenie
Czas kończyć tę epopeję. Jeśli faktycznie doczytałeś do tego momentu i Twoje oczy jeszcze nie krwawią, to gratuluję, masz cierpliwość, choć szczerze wątpię, żeby wielu dotarło do tego akapitu.
Żebyśmy mieli jasność: to, co tu wyżej wypisałem, to tylko taki bardzo ogólny zarys, wręcz liźnięcie tematu przez szybę. Ten system ma tyle funkcji, że próba opisania ich wszystkich w jednym poście skończyłaby się wydaniem encyklopedii. Starałem się po prostu pokazać, że ta platforma to coś więcej niż tylko „zielone ekrany” i księgowość.
Jak będę miał wenę i mi się po prostu zechce, to kiedyś pomęczymy tego „dziadka” czymś bardziej nowoczesnym. Bo choć dla wielu to archaiczny kloc, to pod maską można tam odpalić rzeczy, o które nikt by go nie podejrzewał. Może pogrzebiemy GITem, podepniemy jakiegoś gitlabci albo sprawdzimy, jak tym systemem steruje się Ansiblem (tak, są do tego gotowe kolekcje). Może wrzucimy tam jakiegoś Pythona, Postgresa czy inne MongoDB, żeby zobaczyć, czy ten system sobie z tym poradzi
Zobaczymy, co z tego wyjdzie. Tymczasem dzięki za uwagę i idź przemyć oczy zimną wodą, bo po takiej ilości znaków pewnie ich już nie czujesz.